The Achilles Heel of Modern Electronics
Brent Sorensen
Analog fault monitoring based on neural network technology can be an alternative to conventional digital testing for finding aging-related intermittencies.
Digital measurement technology certainly has taken the test industry forward, mostly with giant strides. The exact opposite may be true, however, when it is applied to testing for aging-related failure modes such as intermittency or no fault found (NFF).
For passive circuit elements such as resistors and capacitors, aging is seen as a continuous or analog type of degradation that results in parameters tending to drift out of tolerance over a very long period of time. In contrast, aging defects in electromechanical and connectivity elements are seen more as randomly occurring, digital-like, intermittent events. In reality, there exist two very distinct failure modes, yet both are being tested for with one technology. In terms of reliability, that is a major problem.
Digital abstraction devices, perfect for parametric testing, rarely synchronize to real-time, randomly occurring, anomalous, or intermittent age-related failure events. This shortcoming is especially acute when large numbers of circuit nodes require testing.
For finding randomly occurring, intermittent failures, all circuits must be tested simultaneously and continuously. By definition, most digital instruments, whether having single or multiplexed inputs, are unsuitable for this task.
Figure 1 compares the capability of various measuring devices to detect intermittencies of varying lengths. For example, a 4.5-digit DMM cannot accurately or reliably discern the presence of an intermittency unless it lasts for at least 200 ms.
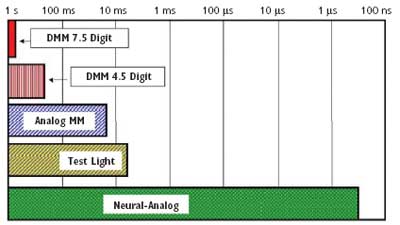
Figure 1. Single Circuit Intermittency Detection Capabilities
The Effects of Poor Reliability
According to several studies, the reliability of certain fielded systems has reached a critical level. The exclusive application of digital instruments has had a particularly devastating effect on all systems under the auspices of the Department of Defense, the FAA, and NASA that use multilayered maintenance schemes where black-box swapping is the preferred diagnostic choice. Even the fleet of the newest Stealth fighters, the F-117s, has been considered for early retirement due to the high expense required to keep the aircraft’s aging avionics systems flight worthy.
Similarly, many automotive and other electrical and electronic manufacturers see their commercial products failing early in their projected life cycles. As a consequence, they are finding themselves at risk of class-action litigation to make right the reliability deficiencies in their market offerings.
In addition to the huge outlay a class-action suit could cost a company, there is the accompanying problem of high warranty return rates with extensive NFF percentages. Closely related are the profit risks some ISO-certified manufacturers will face when quality- and reliability-savvy component buyers refuse to buy undertested components that would put their company in jeopardy.
Wherein Lies the Problem
At the root of most of these early-life intermittent problems, we find degraded circuit connectivity elements such as connectors, crimps, solder joints, relays, switches, and other intermittent-by-design components whose published specifications suffer from the same digital testing deficiency. As a result, their reliability ratings are much higher than reality warrants.
For example, a connector may post super high insertion ratings based on how many times two pins from the connector can be rubbed together before ohmic resistance from fretting reaches some set parametric level, such as 100,000 insertions to reach a 0.2-W level of resistance. However, because the measurement is performed digitally, the point at which the connector first becomes intermittent and essentially unreliable is not known. Actual in-service reliability and product life generally are much shorter than predicted by results of the digital test.
We find products with engineered service lives of several years failing prematurely under warranty due to intermittent interconnections. This occurs even after performing extensive highly accelerated life test/highly accelerated stress screen (HALT/HASS) testing designed to simulate their use well beyond this period.
HALT/HASS testing can miss developing intermittencies if digital instrumentation is used. In the case of run-to-failure testing, the product may itself average out, filter out, or retry an operation using elaborate error correction to fix intermittencies generated by the life-testing process.
While the design team would not condone intermittencies in products that otherwise may be meeting useful life test goals, the testing process itself does not report intermittencies. For that reason, intermittent and unreliable products pass the very screening process designed to catch them.
Despite having used HALT/HASS to produce products meeting significant life objectives, companies have been surprised to find themselves devastated with warranty returns and high NFF due to the unpredictable nature of intermittency as it relates to the aging process. By addressing this one seemingly minor interconnection problem, your system’s life could be extended by several years.
In addition to fretting corrosion, oxidation, loose connections, and bad solder joints, occasionally contaminates from certain manufacturing processes create intermittent discontinuities. For example, an otherwise perfectly good gold-plated connector becomes intermittent because flux and cleaning processes leave an invisible residue on some of the pins.
Also of special note, we see and hear of excessive problems with assemblies or systems that incorporate wire-wrap connections. While not designed to be opened or taken apart, the wrapped connections are neither soldered nor protected from corrosive environmental elements and are virtually impossible to visibly inspect on the contacting surfaces.
Inappropriate Testing for Reliability
The present digital-only testing model cannot certify that an item is free from any age-related or manufacturing-induced intermittency. Functional, component, or continuity testing can only determine that a given test passed certain requirements at a specific moment in time.
There is no rational basis for expecting that these severely limited results could be used to reliably predict the future performance of a product. As an example, you can momentarily open the test leads of a highly accurate DMM by hand then rapidly re-establish continuity, and the meter’s digits may not even blink. Not seeing the glitch is not equal to it didn’t happen.
Because of its mechanical nature, intermittency itself is not linear, repeatable, or predictable. A small, inconsequential, one-shot ohmic glitch one moment may just as easily become a significant wide-open break or short circuit the next.
With aging, the probability of this random intermittent disconnect happening at any level or degree may increase faster than the actual severity of it. For these mechanical connectivity elements to function properly, the relatively rough micromating surfaces, consisting of hundreds or thousands of protruding hills and recessed valleys, must physically make contact on the hills of both surfaces in sufficient numbers to meet design goals.
As fretting wear and oxidation begin to reduce the number of available connecting protrusions, vibrations or thermal expansion that cause the surfaces to slip will tend to create shorter but more numerous micro-intermittencies. As age and wear continue to take their toll, these intermittencies will become more ohmic and longer in duration because of the longer mechanical distances the surfaces may have to travel before continuity is reestablished. As a result of the often subjective demands for higher levels of accuracy in test measurements and the difficulty of digitizing such unpredictable failure events, intermittencies that can reset or shut down a system literally escape detection.
This more numerous microbreak phenomenon actually may be the only good thing about intermittency. While often functionally benign in the beginning stages, with the right testing equipment, they become like red flashing warning lights that a problem is developing that could easily result in more serious operational hazards if left unfixed.
There also is the perceived problem of digital equipment creating false failures or measurement glitches somehow associated with the digital measurement process itself. Upon encountering a glitch or a failed test, some ATE may recycle the test, often numerous times, effectively allowing any real product intermittency to clear itself without logging even a hint of the failure event to the testing record.
The likelihood of seeing an intermittent defect under all of these digitally unique conditions usually is rather small and decreases exponentially as the number of test points increases.
A Simple Example
To enlighten the National Transportation Safety Board’s (NTSB) investigators about the problem of digital averaging during avionics testing of the crash of Flight 587, we put together a rather simple glitch test to demonstrate how today’s digital testing instruments often do not see dangerous latent glitches that can later cause serious problems.
In Figure 2, programmed, one-shot glitches from a pulse generator were fed to a DMM connected to a computer to capture and record the results. The glitches were created at random by dropping an otherwise steady 4-V signal to ground potential 25 times for 100, 10, and 1 ms. The shorter the duration of the applied glitch, the less likely the sampling and averaging digital meter was able to detect it. While a few glitches were completely missed at 100 ms, hardly any registered as defects at 10 ms and 1 ms.
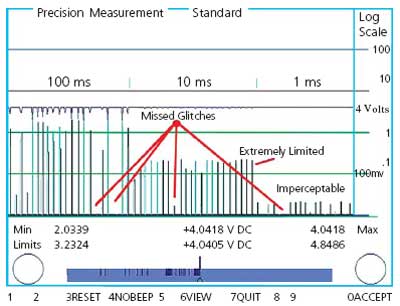
Figure 2. Glitch Testing of a 4.5-Digit DMM
The Solution
Analog testing can resolve the reliability-testing dilemma. While continuous testing overcomes sampling and averaging problems related to digital techniques, there also is the need to test all points simultaneously and do it economically.
For these reasons, we developed neural network technology in a hardware form called the Intermittent Fault Detector/NFF Analyzer. In a neural network, all inputs converge to a common go, no-go output through several layers of analog and eventually digital processing. In the neural network, the incoming glitch is the active element that triggers certain hard-time processing events that automatically yield detection, test-point location, and a digitized trace.
The impact of neural analog technology is found in Figure 3, a screen capture of test results where an expanded glitch test, described in Figure 2, was performed on one of our testers, the Model IFD-2000. Shown as columns that grow with each detected event, the first six test points, color-coded to track results in the scoreboard on the left and the scope traces below, gathered testing data for the applied glitches that ranged in six steps from 100 ms down to 1 µs.
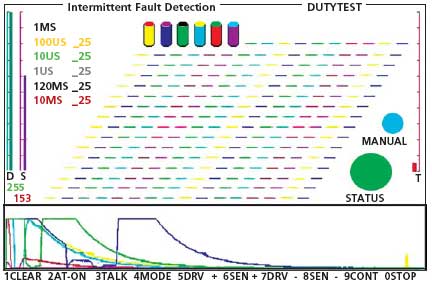
Because all 25 glitches of each pulse duration were software generated, the scope traces on the bottom of the screen overlap and demonstrate perfect repeatability, something not seen with random intermittency. There also were no false failures reported.
For the user, the IFD-2000 is a simple go/no-go device with pass/fail criteria displayed at the top of the screen. The scope traces at the bottom are simply an indication of the severity of any detected intermittency. They only are presented as a diagnostic indicator and to provide a familiar scope-like presentation of what’s going on in the item being evaluated.
Some test engineers have questioned the need for analog neural technology when dozens of equipment manufacturers offer instruments with digital sampling speeds in the gigahertz region. The main problems with this approach are the size and complexity of the instrument that must be configured to simultaneously sample hundreds or thousands of test points and the enormous amounts of digital data that will be acquired at these high speeds. At some time, because an instrument’s storage capability is finite, testing must stop and the data be processed.
With analog neural network technology, the footprint is small, allowing portable applications that analyze for pass/fail in continuous real time, and the only data generated or saved is the failure report. The rest of the information you don’t need.
Perhaps the best example of what this technology brings to the aging-related testing field is illustrated in Figure 4. The more testing information you can gather over a given period of time, the more probable the detection of any anomalous glitches that might be likely to occur during actual operation.
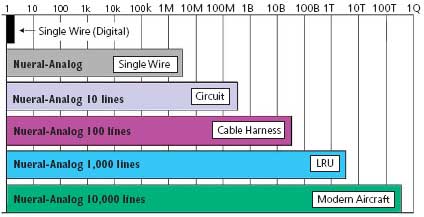
Testing Regardless of the number of lines under test, the glitch detectability
using neural analog technology is 1 event/320 ns.
A popular but mostly futile therapy for NFF or intermittency problems is to run the tests again and again, hoping that something might show up. As can be seen in Figure 4, on a single wire, a 320-ns glitch resolution provides 3.3 million equivalent tests for random intermittency in the same time period that a typical continuity tester using digital technology will perform one test.
Summary
NASA-STD-8729.1 states: “The attribute of reliability, by definition, lies in the probabilistic realm while most performance attributes or parameters such as temperature, speed, thrust, voltage, or material strength contain more deterministic characteristics. Within the accuracy of the measuring devices, one can directly measure performance attributes in the deterministic realm to verify compliance with (reliability) requirements. No such measuring device exists for probabilistic parameters like reliability. It is usually estimated through comparison with similar components or systems through inference, analysis and the use of statistics.”
This view, now superceded by the capability to directly test for reliability with neural analog technology, needs to be updated, especially when intermittency in the connectivity elements is so directly linked to system safety and reliability.
Accurate reliability testing can be seen as increasing return on investment if the costs and the benefits are correctly calculated. Analog intermittency testing costs about 10% of traditional ATE. On older avionics systems where NFF repair rates may run as high as 50% to 90%, the costs of ATE are somehow justified, even for test equipment that is literally only fixing half of the present problems.
Spending a little extra to fix the other half then is indeed a bargain. In most repair or manufacturing situations, the savings from more efficient in-house diagnostics will offset the reliability testing costs, and a company will garner immeasurable goodwill because its now puts out a better, more reliable product and has increased its protection from forced legal remedies.
Brent Sorensen
Related Articles

Maintenance Software Implementation


Maintenance Best Practices: Communication in Maintenance Departments

National Safety Month 2024: Ensuring Worker Safety Through Proactive Facility Maintenance

Practical Guide to Equipment Hierarchy
Bill of Materials: A List of Parts to Streamline Maintenance Work Management


